OI算法复(学)习笔记
双端队列 构造使用deque<int> d即可
用法如下:
q.front() 返回队首元素
q.back() 返回队尾元素
q.push_back() 在队尾插入元素
q.pop_back() 弹出队尾元素
q.push_front() 在队首插入元素
q.pop_front() 弹出队首元素
q.insert() 在指定位置前插入元素
q.erase() 删除指定位置的元素
q.empty() 队列是否为空
q.size() 返回队列中元素的数量
例题:双向动态列车 题目描述
想象一下一列动态列车,这种列车特别之处在于它的首节和末节车厢都可以进行装载和卸载操作。这意味着乘客可以从列车的前端或后端上车,也可以从任何一端下车。
你将获得一系列关于乘客上车和下车的操作,你的任务是在所有操作完成后报告列车最终的乘客状态。
操作指令格式:
LIN X — 将乘客X从列车的前端上车;
RIN X — 将乘客X从列车的后端上车;
LOUT — 从列车的前端让一位乘客下车;
ROUT — 从列车的后端让一位乘客下车。
输入格式
第一行包含一个整数M(M≤10,000M)表示操作的数量。
接下来的M行,每行包含一个操作指令。
输出格式
输出的第一行应描述在进行了M次操作之后列车的状态。从列车的前端到后端输出乘客编号,每两个乘客编号之间用一个空格隔开。
如果存在任何非法的操作(如尝试让乘客从一个空列车的端下车),这些操作的错误应在输出中得到相应的指示。每个非法操作的格式为“X ERROR”,其中X是该操作的序号(从1开始计算)。
解答 分析
使用双端队列进行模拟即可
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <bits/stdc++.h> using namespace std;int a[10005 ];int main () int > d;int m;int cmp=0 ;for (int i=1 ;i<=m;i++){int n;if (s=="LIN" ){push_front (n);else if (s=="RIN" ){push_back (n);else if (s=="LOUT" ){if (d.size ()==0 ){else d.pop_front ();else if (s=="ROUT" ){if (d.size ()==0 ){else d.pop_back ();for (int i=0 ;i<d.size ();i++){" " ;if (cmp>0 ) for (int i=1 ;i<=cmp;i++) cout<<a[i]<<" ERROR" <<endl;return 0 ;
字符串相关用法 string s.substr(int a, int l)可以从s的a(从0开始)截取一个长度为l的字符串
string s.erase(int p,int n) 删除s从p开始的n个字符
string s.insert(int p,string ss) 在s的p位置插入字符串s s
sprintf(char数组s,"%d",int n) 将n转换放置到char数组s中
sscanf(char数组s,"%d",int &n) 将char数组s转换放置到n中
reverse(v.begin(),v.end())或reverse(a+begin,a+end) 反转范围
并查集 引入
有时,你需要知道多个东西之间有没有关系,而时间和空间限制不允许你大手大脚,并查集便应运而生
简介
并查集是一个树形结构,支持合并和查询,通过储存每个点的父亲实现各种操作。而又因为只需要知道各个点之间 有没有关系,所以可以随意选取一个根节点,并且判断操作只需要判断各个点是否在同一棵树内就可以完成,而我们只要比较各点所在树的根节点是否相同就可以,所以只需要存储各点的父亲即可递归查询到根节点进行判断了。
初始化
每个点开始时应当各自为树,各无关系。为了方便我们将父亲为自己的点定义为根节点,因此此处将各个点的父亲定义为自己。
1 2 int p[n+1 ]; for (int i=1 ;i<=n;i++) p[i]=i;
查询
查询是为了找到根节点,很显然可以通过递归查询父亲进行解决。
1 2 3 4 int find (int x) if (p[x]=x) return x; return find (p[x]);
路径压缩
递归还是太浪费时间了,仔细一想我们似乎不需要建立一个常规的树形结构,既然只需要知道每个点的根节点,我们可以直接把每个点连接到根节点上,而这个操作可以边查询边进行。
1 2 3 4 int find (int x) if (p[x]=x) return x; return p[x]=find (p[x]);
合并
将一棵树的根节点连到另一棵树的根节点就好了,当然,由于这个合并操作过于简单,很多情况下也不会将其写成函数。
1 2 3 void unite (int x,int y) find (x)]=find (y);
以上就是并查集的基础要点了,做一道模板题试试水吧。
例题1:P3367 【模板】并查集 题目背景
本题数据范围已经更新到 1 ≤ N ≤ 2 × 10 5 1\le N\le 2\times 10^5 1 ≤ N ≤ 2 × 1 0 5 1 ≤ M ≤ 10 6 1\le M\le 10^6 1 ≤ M ≤ 1 0 6
题目描述
如题,现在有一个并查集,你需要完成合并和查询操作。
输入格式
第一行包含两个整数 N , M N,M N , M N N N M M M
接下来 M M M Z i , X i , Y i Z_i,X_i,Y_i Z i , X i , Y i
当 Z i = 1 Z_i=1 Z i = 1 X i X_i X i Y i Y_i Y i
当 Z i = 2 Z_i=2 Z i = 2 X i X_i X i Y i Y_i Y i Y ;否则输出 N 。
输出格式
对于每一个 Z i = 2 Z_i=2 Z i = 2 Y 或者 N 。
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 4 7 2 1 2 1 1 2 2 1 2 1 3 4 2 1 4 1 2 3 2 1 4
输出 #1
说明/提示
对于 15 % 15\% 15% N ≤ 10 N \le 10 N ≤ 10 M ≤ 20 M \le 20 M ≤ 20
对于 35 % 35\% 35% N ≤ 100 N \le 100 N ≤ 100 M ≤ 10 3 M \le 10^3 M ≤ 1 0 3
对于 50 % 50\% 50% 1 ≤ N ≤ 10 4 1\le N \le 10^4 1 ≤ N ≤ 1 0 4 1 ≤ M ≤ 2 × 10 5 1\le M \le 2\times 10^5 1 ≤ M ≤ 2 × 1 0 5
对于 100 % 100\% 100% 1 ≤ N ≤ 2 × 10 5 1\le N\le 2\times 10^5 1 ≤ N ≤ 2 × 1 0 5 1 ≤ M ≤ 10 6 1\le M\le 10^6 1 ≤ M ≤ 1 0 6 1 ≤ X i , Y i ≤ N 1 \le X_i, Y_i \le N 1 ≤ X i , Y i ≤ N Z i ∈ { 1 , 2 } Z_i \in \{ 1, 2 \} Z i ∈ { 1 , 2 }
解答 分析
模板题,照搬以上讲解内容即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <bits/stdc++.h> using namespace std;const int N=2e5 +5 ;int n,m;int p[N];int find (int x) if (p[x]==x) return x;return p[x]=find (p[x]);void unite (int x,int y) find (x)]=find (y);int main () for (int i=1 ;i<=n;i++) p[i]=i;for (int i=1 ;i<=m;i++){int z,x,y;if (z==1 ){if (find (x)==find (y)) continue ;unite (find (x),find (y));else {if (find (x)==find (y)) cout<<"Y" <<endl;else cout<<"N" <<endl;return 0 ;
当然,单独的并查集确实简单,但是要注意识别和与其他知识点的合用。
例题2:U149298 搭配购买 题目背景
Joe觉得云朵很美,决定去山上的商店买一些云朵。商店里有n朵云,云朵被编号为1,2,……,n,并且每朵云都有一个价值。但是商店老板跟他说,一些云朵要搭配来买才好,所以买一朵云则与这朵云有搭配的云都要买。但是Joe的钱有限,所以他希望尽量买的价值越多越好。
题目描述
无
输入格式
第1行n n n m m m w w w n n n m m m w w w 2 ∼ n + 1 2 \sim n+1 2 ∼ n + 1 c i c_i c i d i d_i d i i i i n + 2 ∼ n + 1 + m n+2 \sim n+1+m n + 2 ∼ n + 1 + m u i u_i u i v i v_i v i u i u_i u i v i v_i v i v i v_i v i u i u_i u i
输出格式
一行,表示可以获得的最大价值
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 9 5 3 10 3 10 3 10 3 10 5 100 10 1 1 3 3 2 4 2
输出 #1
说明/提示
30 % 30\% 30% n ≤ 100 n \le 100 n ≤ 100
50 % 50\% 50% n ≤ 1 , 000 n \le 1,000 n ≤ 1 , 000 m ≤ 100 m \le 100 m ≤ 100 w ≤ 1 , 000 w \le 1,000 w ≤ 1 , 000
100 % 100\% 100% n ≤ 10 , 000 n \le 10,000 n ≤ 10 , 000 0 ≤ m ≤ 5000 0 \le m \le 5000 0 ≤ m ≤ 5000 w ≤ 10 , 000 w \le 10,000 w ≤ 10 , 000
解答 分析
因为云朵需要搭配来买,所以可以用并查集将代价和价值捆绑到一起,接下来就转换成了一个01背包问题。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <bits/stdc++.h> using namespace std;const int N=1e4 +5 ;int n,m,w;int p[N],c[N],d[N];int find (int x) if (p[x]==x) return x;return p[x]=find (p[x]);void unite (int x,int y) int a=find (x),b=find (y);if (a!=b){p[a]=b;c[b]+=c[a];d[b]+=d[a];} int f[N];int main () for (int i=1 ;i<=n;i++) p[i]=i;for (int i=1 ;i<=n;i++) cin>>c[i]>>d[i];int u,v;for (int i=1 ;i<=m;i++){unite (u,v);for (int i=1 ;i<=n;i++){if (p[i]!=i) continue ;for (int j=w;j>=c[i];j--){max (f[j],f[j-c[i]]+d[i]);
拓展并查集
有时,我们不只需要储存朋友关系,还需要储存敌人关系。我们知道并查集只能储存朋友,而不能储存敌人,所以我们可以用拓展并查集将敌人放进并查集中。
如何将敌人用朋友的方式标识出来呢?我们知道敌人的敌人就是朋友,所以不妨设一共有n个人,我们定义第a+n个点是第a个点的敌人,如果a与b是敌人,我们只需要让a和b+n成为朋友,a+n和b成为朋友,问题便迎刃而解。
接下来做一道模板题试一试吧!
例题3:盟友与宿敌 描述
在某个奇妙的魔法世界里,许多魔法师聚集在一起进行一场大型魔法竞技。他们之间有着复杂的关系:有些是盟友,有些则是宿敌。
规则如下:
1.我的盟友的盟友,也是我的盟友;
我的宿敌的宿敌,是我的盟友;
两个人只要是盟友,就认为他们属于同一魔法团队。
现在,给你若干魔法师之间的关系,请问:最多可以有多少个独立的魔法团队?
输入描述
第一行是一个整数N ( 2 ≤ N ≤ 1000 ) N(2\le N\le 1000) N ( 2 ≤ N ≤ 1000 )
第二行是一个整数M ( 1 ≤ M ≤ 5000 ) M(1\le M\le5000) M ( 1 ≤ M ≤ 5000 )
以下M行,每行可能是F p q或E p q( 1 ≤ p , q ≤ N ) (1\le p,q\le N) ( 1 ≤ p , q ≤ N )
输入数据保证不会产生信息的矛盾。
输出描述
输出文件只有一行,表示最大可能的魔法团队数。
解答 分析
使用拓展并查集进行模拟即可,因为要求找到魔法团队数,所以可以使用自动去重的set进行遍历根节点。
###标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;int n,m;int p[2010 ];int find (int x) if (p[x]==x) return x;return p[x]=find (p[x]);void unite (int x,int y) find (x)]=find (y);int > s;int main () for (int i=1 ;i<=2 *n;i++) p[i]=i;char r;int p,q;while (m--){if (r=='F' ) unite (p,q);else {unite (p,q+n);unite (p+n,q);}for (int i=1 ;i<=n;i++) s.insert (find (i));size ();
接下来我们做两道比较难的拓展并查集题目。
例题4:P2024 [NOI2001] 食物链 题目描述
动物王国中有三类动物 A , B , C A,B,C A , B , C A A A B B B B B B C C C C C C A A A
现有 N N N 1 ∼ N 1 \sim N 1 ∼ N A , B , C A,B,C A , B , C
有人用两种说法对这 N N N
第一种说法是 1 X Y,表示X和Y是同类。
第二种说法是 2 X Y,表示X吃Y。
此人对 N N N K K K K K K
当前的话与前面的某些真的话冲突,就是假话;
当前的话中X或Y比N大,就是假话;
当前的话表示X吃X,就是假话。
你的任务是根据给定的 N N N K K K
输入格式
第一行两个整数,N , K N,K N , K N N N K K K
第二行开始每行一句话。格式见题目描述与样例。
输出格式
一行,一个整数,表示假话的总数。
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 9 100 7 1 101 1 2 1 2 2 2 3 2 3 3 1 1 3 2 3 1 1 5 5
输出 #1
说明/提示
对于全部数据,1 ≤ N ≤ 5 × 10 4 1\le N\le 5 \times 10^4 1 ≤ N ≤ 5 × 1 0 4 1 ≤ K ≤ 10 5 1\le K \le 10^5 1 ≤ K ≤ 1 0 5
解答 分析
显然,由于有三种动物,所以拓展并查集需要开三倍大小,具体动物种类对问题没有影响。
对于判断假话环节,x或y比n大和x吃x很好解决,难点在于判断是否和前面冲突。
我们有这样一个关系图:
如果他告诉我们x和y是同一种动物。但是实际上,x和y+n是一家的或者x和y+2n是一家的,这样两者是冲突的。
如果不冲突,直接合并x和y,x+n和y+n,x+2n和y+2n就可以了。
如果他告诉我们x能吃y,即x和吃y的人是一家的,即x和y+2n是一家的。但是若x和y是一家的,x和y+n(y的食物)是一家的,两者冲突。
如果不冲突,直接合并x和y+2n,x+n和y,x+2n和y+n就可以了。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <bits/stdc++.h> using namespace std;const int N=5e4 +5 ;int n,k;int p[3 *N];int find (int x) if (p[x]==x) return x;return p[x]=find (p[x]);void unite (int x,int y) find (x)]=find (y);int main () int a,x,y;int cnt=0 ;for (int i=1 ;i<=3 *n;i++) p[i]=i;while (k--){if (x>n||y>n){cnt++;continue ;} if (x==y&&a==2 ){cnt++;continue ;} if (a==1 ){if (find (x)==find (y+n)||find (x)==find (y+2 *n)){cnt++;continue ;}unite (x,y);unite (x+n,y+n);unite (x+n*2 ,y+n*2 );else if (a==2 ){if (find (x)==find (y)||find (x)==find (y+n)){cnt++;continue ;}unite (x+n,y);unite (x+2 *n,y+n);unite (x,y+n*2 );
例题5:P1525 [NOIP 2010 提高组] 关押罪犯 题目背景
NOIP2010 提高组 T3
题目描述
S 城现有两座监狱,一共关押着 N N N 1 ∼ N 1\sim N 1 ∼ N c c c c c c
每年年末,警察局会将本年内监狱中的所有冲突事件按影响力从大到小排成一个列表,然后上报到 S 城 Z 市长那里。公务繁忙的 Z 市长只会去看列表中的第一个事件的影响力,如果影响很坏,他就会考虑撤换警察局长。
在详细考察了 N N N
那么,应如何分配罪犯,才能使 Z 市长看到的那个冲突事件的影响力最小?这个最小值是多少?
输入格式
每行中两个数之间用一个空格隔开。第一行为两个正整数 N , M N,M N , M M M M a j , b j , c j a_j,b_j,c_j a j , b j , c j a j a_j a j b j b_j b j c j c_j c j 1 ≤ a j < b j ≤ N , 0 < c j ≤ 10 9 1\le a_j< b_j\leq N, 0 < c_j\leq 10^9 1 ≤ a j < b j ≤ N , 0 < c j ≤ 1 0 9
输出格式
共一行,为 Z 市长看到的那个冲突事件的影响力。如果本年内监狱中未发生任何冲突事件,请输出 0。
输入输出样例 #1
输入 #1
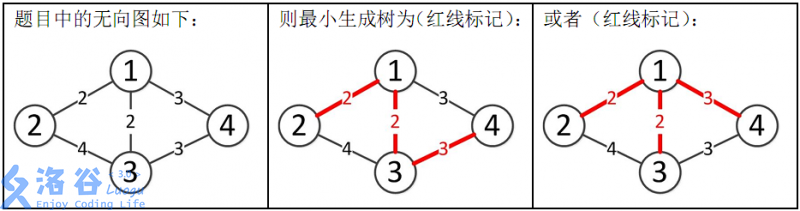
1 2 3 4 5 6 7 4 6 1 4 2534 2 3 3512 1 2 28351 1 3 6618 2 4 1805 3 4 12884
输出 #1
说明/提示
输入输出样例说明
罪犯之间的怨气值如下面左图所示,右图所示为罪犯的分配方法,市长看到的冲突事件影响力是 3512 3512 3512 2 2 2 3 3 3
数据范围
对于 30 % 30\% 30% N ≤ 15 N\leq 15 N ≤ 15
对于 70 % 70\% 70% N ≤ 2000 , M ≤ 50000 N\leq 2000,M\leq 50000 N ≤ 2000 , M ≤ 50000
对于 100 % 100\% 100% N ≤ 20000 , M ≤ 100000 N\leq 20000,M\leq 100000 N ≤ 20000 , M ≤ 100000
解答 分析
先将所有可能的冲突从大到小进行排序,依次解决,用并查集记录,知道有一个无法解决的就是答案。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <bits/stdc++.h> using namespace std;int n,m;int p[40005 ];struct node {int a,b,c;100005 ];bool cmp (node x,node y) return x.c>y.c;int find (int x) if (p[x]==x) return x;return p[x]=find (p[x]);void unite (int x,int y) find (x)]=find (y);int main () int a,b,c;for (int i=1 ;i<=n*2 ;i++) p[i]=i;for (int i=1 ;i<=m;i++){sort (x+1 ,x+m+1 ,cmp);for (int i=1 ;i<=m;i++){if (find (x[i].a)==find (x[i].b)){cout<<x[i].c<<endl;return 0 ;}unite (x[i].a,x[i].b+n);unite (x[i].a+n,x[i].b);0 <<endl;
最小生成树 最小生成树就是无向连通图中边权和最小的一棵树。
Kruskal 算法
Kruskal算法是一种非常简单的贪心算法,原理是为了让总边权最小,从小到大连接各边,同时使用并查集保证是一棵树。
具体实现需要先将各边排序,然后检测边是否能构成一颗树,如果可以就连接。
核心代码如下:
1 2 3 4 5 6 7 8 9 10 void zuixiao () sort (a+1 ,a+m+1 ,cmp); for (int i=1 ;i<=m;i++){int p=find (a[i].x),q=find (a[i].y); if (p==q) continue ; if (cnt==n-1 ) break ;
来做一道模板题吧!
例题1:P3366 【模板】最小生成树 题目描述
如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出 orz。
输入格式
第一行包含两个整数 N , M N,M N , M N N N M M M
接下来 M M M X i , Y i , Z i X_i,Y_i,Z_i X i , Y i , Z i Z i Z_i Z i X i , Y i X_i,Y_i X i , Y i
输出格式
如果该图连通,则输出一个整数表示最小生成树的各边的长度之和。如果该图不连通则输出 orz。
输入输出样例 #1
输入 #1
1 2 3 4 5 6 4 5 1 2 2 1 3 2 1 4 3 2 3 4 3 4 3
输出 #1
说明/提示
数据规模:
对于 20 % 20\% 20% N ≤ 5 N\le 5 N ≤ 5 M ≤ 20 M\le 20 M ≤ 20
对于 40 % 40\% 40% N ≤ 50 N\le 50 N ≤ 50 M ≤ 2500 M\le 2500 M ≤ 2500
对于 70 % 70\% 70% N ≤ 500 N\le 500 N ≤ 500 M ≤ 10 4 M\le 10^4 M ≤ 1 0 4
对于 100 % 100\% 100% 1 ≤ N ≤ 5000 1\le N\le 5000 1 ≤ N ≤ 5000 1 ≤ M ≤ 2 × 10 5 1\le M\le 2\times 10^5 1 ≤ M ≤ 2 × 1 0 5 1 ≤ Z i ≤ 10 4 1\le Z_i \le 10^4 1 ≤ Z i ≤ 1 0 4 1 ≤ X i , Y i ≤ N 1\le X_i,Y_i\le N 1 ≤ X i , Y i ≤ N
样例解释:
所以最小生成树的总边权为 2 + 2 + 3 = 7 2+2+3=7 2 + 2 + 3 = 7
解答 分析
模板,没什么好说的。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <bits/stdc++.h> using namespace std;const int N=5005 ,M=2e5 +5 ;int n,m;int fa[N];struct node {int x,y,z; int find (int x) if (fa[x]==x) return x;return fa[x]=find (fa[x]);bool cmp (node x,node y) return x.z<y.z;int ans=0 ,cnt=0 ;void zuixiao () sort (a+1 ,a+m+1 ,cmp);for (int i=1 ;i<=m;i++){int p=find (a[i].x),q=find (a[i].y);if (p==q) continue ;if (cnt==n-1 ) break ; int main () for (int i=1 ;i<=n;i++) fa[i]=i;for (int i=1 ;i<=m;i++) cin>>a[i].x>>a[i].y>>a[i].z;zuixiao ();if (cnt<n-1 ) cout<<"orz" <<endl;else cout<<ans<<endl;
当然,最小生成树经过略微变形,同样可以解决最小生成森林问题。
例题2:星际纺织工 描述
小光坐在飞船的舱室中,凝望通过舷窗看到的繁星点点的宇宙。
星际间流淌着五彩的星尘,就如同梦幻场景,小光想通过这些美丽的星尘编织几个星球间的星尘丝带。
宇宙中有N个星球,小光手上有M份星际地图,每份地图描绘了哪些星球之间可以用星尘编织。
现在小光要将所有星球通过星尘编织成K个星尘丝带,一个星尘丝带至少要连接一个星球,小光想知道他怎样编织,星尘的消耗最少。
输入描述
第一行有三个数字N,M,K
接下来M行,每行包含三个数值X,Y,L,表示星球X和星球Y可以用消耗L的星尘数量编织连接。
输出描述
对每组数据输出一行,仅包含一个整数 —— 最小的消耗代价。
如果无论如何都不能编织出K个星尘丝带,请输出 No Answer。
解答 分析
显然,题意等价于要求我们生成k个最小生成树。
而我们知道因为N个点,有N−K条边即可保证形成K个连通块,所以用N-K作为结束条件即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <bits/stdc++.h> using namespace std;const int N=1e4 +5 ;int n,m,k;int p[1005 ];struct node {int x,y,l; int find (int x) if (p[x]==x) return x;return p[x]=find (p[x]);bool cmp (node x,node y) return x.l<y.l;int cnt=0 ,ans=0 ;void zuixiao () sort (a+1 ,a+m+1 ,cmp);for (int i=1 ;i<=m;i++){int b=find (a[i].x),c=find (a[i].y);if (b==c) continue ;if (cnt==n-k) break ;if (cnt<n-k) ans=-1 ;int main () for (int i=1 ;i<=n;i++) p[i]=i;for (int i=1 ;i<=m;i++) cin>>a[i].x>>a[i].y>>a[i].l;zuixiao ();if (ans==-1 ) cout<<"No Answer" ;else cout<<ans;return 0 ;
快速幂 极为基础的知识点,将取幂的任务按照指数的二进制表示来分割成更小的任务
标程如下:
1 2 3 4 5 6 long long binpow (long long a,long long b,long long p) if (b==0 ) return 1 ; long long res=binpow (a,b/2 ,p);if (b%2 ) return res*res%p*a%p; return res*res%p;
最大公约数 常用的求最大公约数的方法有两种:
1 2 3 4 5 6 int gcd (int a,int b) if (b==0 ) return a;return gcd (b,a%b);
如果要求最小公倍数也不难:
1 2 3 4 5 int lcm (int a,int b) return a*b/gcd (a,b);
质数 检验质数
1 2 3 4 5 6 7 bool isprime (int x) if (n==1 ) return 0 ;for (int i=2 ;i<=sqrt (x);i++){ if (x%i==0 ) return 0 ; return 1 ;
对于找质数,常用的不是检验的方法,而是筛法,将合数筛掉,但值得一提的是检验法是在线算法,给它一个检验一个,而筛法是离线算法,一下把范围内的质数都找出来。
找质数:埃拉托斯特尼筛法
质数的倍数一定不是质数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vector<int > prime;bool isprime[N];void findprime (int n) 0 ]=isprime[1 ]=false ;for (int i=2 ;i<=n;i++) isprime[i]=true ;for (int i=2 ;i<=n;i++){if (isprime[i]){push_back (i);if (i*i>n) continue ; for (int j=i*i;j<=n;j+=i) false ;
找质数:欧拉筛法
不难发现,埃氏筛法中很多数会被重复筛掉,例如6会被2和3都筛一次,很浪费时间,欧拉筛法(又名线性筛法)便应运而生。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vector<int > prime;bool notprime[N];void euler (int n) for (int i=2 ;i<=n;i++){if (notprime[i]==0 ) prime.push_back (i);for (int pri:prime){if (i*pri>n) break ; true ;if (i%pri==0 ) break ;
做一道线性筛模板练手吧!
例题1:素数个数 描述
求1,2,…,N中素数的个数
输入描述
一行一个整数N
输出描述
一行一个整数,表示素数的个数。
解答 分析
欧拉筛得出范围内所有质数,然后用size得出prime大小即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <bits/stdc++.h> using namespace std;const int N=1e8 +5 ;int n;int > prime;bool notprime[N];void euler () for (int i=2 ;i<=n;i++){if (notprime[i]==0 ) prime.push_back (i);for (int pri:prime){if (i*pri>n) break ;true ;if (i%pri==0 ) break ;int main () euler ();size (); return 0 ;
经过思考,我们不难发现,由于线性筛不会重复筛除,所以求质数的同时也得到了每个数的最小质因子。
例题2:B4272 [蓝桥杯青少年组省赛 2023] 质因数的个数 题目背景
因数 :又称为约数,如果整数 a a a b ( b ≠ 0 ) b(b\neq 0) b ( b = 0 ) b b b a a a
质数 :又称为素数,一个大于 1 1 1 1 1 1 2 2 2
质因数 :如果一个数 a a a b b b b b b a a a 8 = 2 × 2 × 2 8=2\times 2\times2 8 = 2 × 2 × 2 2 2 2 8 8 8 12 = 2 × 2 × 3 12=2\times 2\times 3 12 = 2 × 2 × 3 2 2 2 3 3 3 12 12 12
题目描述
给定两个正整数 N N N M ( 1 ≤ N ≤ M ≤ 10 7 ) M(1\leq N\leq M\leq 10^7) M ( 1 ≤ N ≤ M ≤ 1 0 7 ) N N N M M M N N N M M M
例如:当 N = 6 , M = 10 N=6,M=10 N = 6 , M = 10 6 6 6 10 10 10
6 6 6 2 , 3 2,3 2 , 3 2 2 2
7 7 7 7 7 7 1 1 1
8 8 8 2 , 2 , 2 2,2,2 2 , 2 , 2 3 3 3
9 9 9 3 , 3 3,3 3 , 3 2 2 2
10 10 10 2 , 5 2,5 2 , 5 2 2 2
6 6 6 10 10 10 8 8 8 3 3 3 3 3 3
输入格式
输入两个正整数 N N N M ( 1 ≤ N ≤ M ≤ 10 7 ) M(1\leq N\leq M\leq 10^7) M ( 1 ≤ N ≤ M ≤ 1 0 7 )
输出格式
输出一个整数,表示质因数个数中的最大值。
输入输出样例 #1
输入 #1
输出 #1
解答 分析
首先很显然可以通过线性筛筛出每个数的最小质因数,又很显然,假设i的最小质因数是p,那么i的总质因数个数等于i/p的质因数个数+1!据此模拟即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <bits/stdc++.h> using namespace std;const int N=1e7 +5 ;int > prime;bool notprime[N];int minprime[N];int n,m;int cnt[N];void eular () 0 ] = cnt[1 ] = 0 ;for (int i=2 ;i<=m;++i){if (!notprime[i]) prime.push_back (i),minprime[i]=i,cnt[i]=1 ;else cnt[i]=cnt[i/minprime[i]]+1 ;for (int p:prime){if (i*p>m) break ;true ;if (i%p==0 ){break ;}int main () eular ();int maxx=-1 ;for (int i=n;i<=m;i++){max (maxx,cnt[i]);return 0 ;
裴蜀定理 裴蜀定理
很好理解,若有一个方程ax+by=d,有且只有当d为gcd(a,b)时方程才有整数解,而且可以推导出a与b互质当且仅当存在x,y满足ax+by=1.
很有趣的,裴蜀定理可以进行推广,存在整数 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x 1 , x 2 , ⋯ , x n gcd ( a 1 , a 2 , ⋯ , a n ) = a 1 x 1 + a 2 x 2 + ⋯ + a n x n \gcd(a_1,a_2,\cdots,a_n)=a_1x_1+a_2x_2+\cdots+a_nx_n g cd( a 1 , a 2 , ⋯ , a n ) = a 1 x 1 + a 2 x 2 + ⋯ + a n x n
现在来做一道简单的题吧!
例题1:裴蜀定理 描述
给定一个包含n个元素的整数序列A,记作A 1 , A 2 , A 3 , . . . , A n A_1,A_2,A_3,...,A_n A 1 , A 2 , A 3 , ... , A n
求另一个包含n个元素的待定整数序列X,记 S = ∑ i = 1 n A i × X i S=\sum_{i=1}^{n} A_i \times X_i S = ∑ i = 1 n A i × X i S > 0 S>0 S > 0 S S S
输入描述
第一行一个整数n,表示序列元素个数。
第二行n个整数,表示序列A。
输出描述
一行一个整数,表示
解答 分析
就是推广裴蜀定理,求出总的gcd即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <bits/stdc++.h> using namespace std;int n;int main () int ans=0 ;while (n--){int a;abs (a);return 0 ;
拓展欧几里得
那么面对ax+by=gcd(a,b)时我们怎么求x和y呢?
此时我们可以使用拓展欧几里得算法!
a x 1 + b y 1 = gcd ( a , b ) ax_1+by_1=\gcd(a,b) a x 1 + b y 1 = g cd( a , b )
b x 2 + ( a m o d b ) y 2 = gcd ( b , a m o d b ) bx_2+(a \bmod b)y_2=\gcd(b,a \bmod b) b x 2 + ( a mod b ) y 2 = g cd( b , a mod b )
由欧几里得定理可知:gcd ( a , b ) = gcd ( b , a m o d b ) \gcd(a,b)=\gcd(b,a \bmod b) g cd( a , b ) = g cd( b , a mod b )
所以 a x 1 + b y 1 = b x 2 + ( a m o d b ) y 2 ax_1+by_1=bx_2+(a \bmod b)y_2 a x 1 + b y 1 = b x 2 + ( a mod b ) y 2
又因为 a m o d b = a − ( ⌊ a b ⌋ × b ) a \bmod b=a-(\lfloor\frac{a}{b}\rfloor \times b) a mod b = a − (⌊ b a ⌋ × b )
所以 a x 1 + b y 1 = b x 2 + ( a − ( ⌊ a b ⌋ × b ) ) y 2 ax_1+by_1=bx_2+(a-(\lfloor\frac{a}{b}\rfloor \times b))y_2 a x 1 + b y 1 = b x 2 + ( a − (⌊ b a ⌋ × b )) y 2
a x 1 + b y 1 = a y 2 + b x 2 − ⌊ a b ⌋ × b y 2 = a y 2 + b ( x 2 − ⌊ a b ⌋ y 2 ) ax_1+by_1=ay_2+bx_2-\lfloor\frac{a}{b}\rfloor \times by_2=ay_2+b(x_2-\lfloor\frac{a}{b}\rfloor y_2) a x 1 + b y 1 = a y 2 + b x 2 − ⌊ b a ⌋ × b y 2 = a y 2 + b ( x 2 − ⌊ b a ⌋ y 2 )
因为 a = a , b = b a=a,b=b a = a , b = b x 1 = y 2 , y 1 = x 2 − ⌊ a b ⌋ y 2 x_1=y_2,y_1=x_2-\lfloor\frac{a}{b}\rfloor y_2 x 1 = y 2 , y 1 = x 2 − ⌊ b a ⌋ y 2
将x 2 , y 2 x_2,y_2 x 2 , y 2
具体实现如下:
1 2 3 4 5 6 7 8 9 int exgcd (int a,int b,int &x,int &y) if (b==0 ){1 ,y=1 ; return a;int d=exgcd (b,a%b,x,y),t=x;return d;
当然,既然叫exgcd,返回的d也是a和b的gcd。
还有一个问题,事实上,由于d一定是gcd(a,b)的倍数,所以我们求得的x和y其实是被等比缩小的结果,故而如果要使用时有必要进行扩倍。
线性同余方程
求解线性同余方程是裴蜀定理常见的应用。
线性同余方程就是形如𝑎𝑥≡𝑏(mod𝑛)的方程,它可以转换成ax+𝑛𝑦=𝑏.所以可以使用拓展欧几里得进行求解。
当然,只有当b是gcd(a,n)的整数倍时方程才有解。
接下来尝试写一下吧!
例题1:线性同余方程 描述
给定n组数据a i , b i , m i a_i,b_i,m_i a i , b i , m i x i x_i x i a i × x i ≡ b i ( m o d m i ) a_i×x_i≡b_i(mod m_i) a i × x i ≡ b i ( m o d m i )
输入描述
第一行包含整数n。接下来n行,每行包含一组数据 a i , b i , m i a_i,b_i,m_i a i , b i , m i
输出描述
输出共n行,每组数据输出一个整数表示一个满足条件的x i x_i x i
每组数据结果占一行,结果可能不唯一,输出任意一个满足条件的结果均可。
输出答案必须在 int 范围之内。
解答 分析
题意很好理解,写的时候注意将x扩倍即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <bits/stdc++.h> using namespace std;#define int long long int n,a,b,m,x,y;int exgcd (int a,int b,int &x,int &y) if (!b){1 ;0 ;return a;int d=exgcd (b,a%b,y,x);return d;signed main () while (n--){int d=exgcd (a,m,x,y); if (b%d!=0 ) cout<<"impossible" <<endl;else { return 0 ;
逆元
对于非零整数a,m,如果存在b使得a b ≡ 1 ( m o d m ) ab\equiv 1\pmod m ab ≡ 1 ( mod m )
显然,仅当gcd(a,m)=1时(即两数互质),存在逆元,而b/d就等于1,所以逆元就是x自己,不必扩倍。
标程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <bits/stdc++.h> using namespace std;#define int long long int n,a,b,x,y;int exgcd (int a,int b,int &x,int &y) if (!b){1 ;0 ;return a;int d=exgcd (b,a%b,y,x);return d;signed main () while (n--){int d=exgcd (a,b,x,y);if (d!=1 ) cout<<"impossible" <<endl;else cout<<(x%b+b)%b<<endl;return 0 ;
RMQ问题(ST表) RMQ问题
RMQ问题说白了就是要求快速求解区间最大值或最小值的问题,很显然,问题难度在于时间复杂度。
ST表
ST表又名稀疏表,基于倍增思想,用于求解区间性问题。如果你不知道什么是倍增,只要记住和2的幂有关,将复杂度降成log的。
在这里,我们定义一个二维数组st[N][M],st[i][j]表示从i开始向后2 j 2^j 2 j
接下来我将讲解实现过程。
###初始化
根据定义,st表使用动态规划的初始化方式。
很显然,st[i][0]就是这个数本身,而且只有知道这个初始值才能进行之后的初始化。那么ST表的初始化就要使用双层循环,外层是j,内层是i,具体的初始化则是st[i][j]=max(st[i][j-1],st[i+(1<<(j-1))][j-1])这样的简单方式。
计算
在进行计算从l到r的极值时可能会出现问题,那就是l和r不是2的整数次幂,这时我们可以将其分成两部分,最终答案就是两部分的最大值的最大值。
这两部分应当如何划分呢?
很显然,l和r中间总共能分到的2的次幂就是log2(r-l+1),不妨将其定义为k。
当然,第一部分就可以是st[l][k]。
而第二部分则出现了问题,应当是从第一部分向后推还是从r向前推呢?
我们思考一下,由于C++函数下取整的缘故,st[l][k]的查询范围定然小于等于lr的范围,但是st[l][2*k]的范围又一定会超过l r的范围,这很可能会导致我们的查询出现错误,万一范围内有一个更大的数字怎么办呢对吧。所以max(st[l][k],st[l+(1<<k)+1][k])是行不通的。
那么我们考虑一下从r向前推,不难证明,r向前k个数和l向后k个数是一定能够覆盖整个范围的,且不会超过范围。虽然两者的范围可能会有重叠,但是宁多勿少嘛!
那么最终的公式就是max(st[l][k],st[r-(1<<k)+1][k])了!
接下来不妨做一道模板题吧!
例题1:P3865 【模板】ST 表 & RMQ 问题 题目背景
这是一道 ST 表经典题——静态区间最大值
请注意最大数据时限只有 0.8s,数据强度不低,请务必保证你的每次查询复杂度为 O ( 1 ) O(1) O ( 1 )
如果您认为您的代码时间复杂度正确但是 TLE,可以尝试使用快速读入:
1 2 3 4 5 6 7 inline int read () int x=0 ,f=1 ;char ch=getchar ();while (ch<'0' ||ch>'9' ){if (ch=='-' ) f=-1 ;ch=getchar ();}while (ch>='0' &&ch<='9' ){x=x*10 +ch-48 ;ch=getchar ();}return x*f;
函数返回值为读入的第一个整数。
快速读入作用仅为加快读入,并非强制使用。
题目描述
给定一个长度为 N N N M M M
输入格式
第一行包含两个整数 N , M N,M N , M
第二行包含 N N N a i a_i a i i i i
接下来 M M M l i , r i l_i,r_i l i , r i [ l i , r i ] [l_i,r_i] [ l i , r i ]
输出格式
输出包含 M M M
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 9 10 8 8 9 3 1 7 5 6 0 8 1 6 1 5 2 7 2 6 1 8 4 8 3 7 1 8
输出 #1
说明/提示
对于 30 % 30\% 30% 1 ≤ N , M ≤ 10 1\le N,M\le 10 1 ≤ N , M ≤ 10
对于 70 % 70\% 70% 1 ≤ N , M ≤ 10 5 1\le N,M\le {10}^5 1 ≤ N , M ≤ 10 5
对于 100 % 100\% 100% 1 ≤ N ≤ 10 5 1\le N\le {10}^5 1 ≤ N ≤ 10 5 1 ≤ M ≤ 2 × 10 6 1\le M\le 2\times{10}^6 1 ≤ M ≤ 2 × 10 6 a i ∈ [ 0 , 10 9 ] a_i\in[0,{10}^9] a i ∈ [ 0 , 10 9 ] 1 ≤ l i ≤ r i ≤ N 1\le l_i\le r_i\le N 1 ≤ l i ≤ r i ≤ N
解答 模板,按照讲解做即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;const int N=1e5 +5 ;int n,m;int a[N],st[N][17 ];void init () for (int j=0 ;j<17 ;j++){for (int i=1 ;i+(1 <<j)-1 <=n;i++){if (j==0 ) st[i][j]=a[i];else st[i][j]=max (st[i][j-1 ],st[i+(1 <<(j-1 ))][j-1 ]);void query (int l,int r) int k=log2 (r-l+1 );int ans=max (st[l][k],st[r-(1 <<k)+1 ][k]);int main () for (int i=1 ;i<=n;i++) cin>>a[i];init ();for (int i=1 ;i<=m;i++){int l,r;query (l,r);return 0 ;
接下来做一道实战吧!
例题2:P2880 [USACO07JAN] Balanced Lineup G 题目描述
每天,农夫 John 的 n ( 1 ≤ n ≤ 5 × 10 4 ) n\ (1\le n\le 5\times 10^4) n ( 1 ≤ n ≤ 5 × 1 0 4 )
有一天,John 决定让一些牛们玩一场飞盘比赛。他准备找一群在队列中位置连续的牛来进行比赛。但是为了避免水平悬殊,牛的身高不应该相差太大。John 准备了 q ( 1 ≤ q ≤ 1.8 × 10 5 ) q\ (1\le q\le 1.8\times10^5) q ( 1 ≤ q ≤ 1.8 × 1 0 5 ) h i ( 1 ≤ h i ≤ 10 6 , 1 ≤ i ≤ n ) h_i\ (1\le h_i\le 10^6,1\le i\le n) h i ( 1 ≤ h i ≤ 1 0 6 , 1 ≤ i ≤ n )
输入格式
第一行两个数 n , q n,q n , q
接下来 n n n h i h_i h i
再接下来 q q q a a a b b b a a a b b b
输出格式
输出共 q q q
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 9 10 6 3 1 7 3 4 2 5 1 5 4 6 2 2
输出 #1
解答 分析
就是多了一个最小值,完全同理。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std;const int N=5e4 +5 ;int n,q;int h[N];int stmax[N][17 ],stmin[N][17 ];void init () for (int j=0 ;j<17 ;j++){for (int i=1 ;i+(1 <<j)-1 <=n;i++){if (j==0 ) stmax[i][j]=h[i],stmin[i][j]=h[i];else stmax[i][j]=max (stmax[i][j-1 ],stmax[i+(1 <<(j-1 ))][j-1 ]),stmin[i][j]=min (stmin[i][j-1 ],stmin[i+(1 <<(j-1 ))][j-1 ]);void search (int a,int b) int k=log2 (b-a+1 );int maxx=max (stmax[a][k],stmax[b-(1 <<k)+1 ][k]);int minn=min (stmin[a][k],stmin[b-(1 <<k)+1 ][k]);int main () for (int i=1 ;i<=n;i++) cin>>h[i];init ();for (int i=1 ;i<=q;i++){int a,b;search (a,b);return 0 ;
LCA(倍增法) LCA
LCA就是树上两点的最近公共祖先。
实现
当然,求解这个问题我们首先想到的就是朴素算法,即从两个点一个一个往上找,相交的点就是LCA。很显然,这个算法的时间复杂度直接爆炸。
我们知道一个性质,所有的自然数都可以通过若干个2的次幂相加得到,这样我们可以使用贪心算法,一次不一个一个找,而是直接向上走2的尽量多次幂。
实现时可以定义一个数组,存储第i个点向上找2 j 2^j 2 j
详细步骤参见标程,还是挺好理解的。
标程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <bits/stdc++.h> using namespace std;const int N=5e5 +5 ;int n,m,s; int > p[N]; int depth[N],fa[N][20 ]; void dfs (int u,int parent) 0 ]=parent;for (int i=1 ;i<20 ;i++){ -1 ]][i-1 ]; for (int v:p[u]){ if (v!=parent){+1 ; dfs (v,u); int lca (int x,int y) if (depth[x]<depth[y]) swap (x,y); for (int i=19 ;i>=0 ;i--){if (depth[fa[x][i]]>=depth[y]){if (x==y) return x; for (int i=19 ;i>=0 ;i--){ if (fa[x][i]!=fa[y][i]){ return fa[x][0 ]; int main () for (int i=1 ;i<=n-1 ;i++){int a,b;push_back (b);push_back (a);1 ; dfs (s,0 ); for (int i=1 ;i<=m;i++){int x,y;lca (x,y)<<endl;return 0 ;
树状数组 引入
有时,我们需要求解范围内的区间问题,例如我要求解1~n的任意两个数之间的前缀和,如果我将其依次相加,时间复杂度就是O(n),但是如果我将它拆成若干个区间再合并,它的时间复杂度至少可以是O(logn)!这就是树状数组!(有点类似之前的RMQ)
使用
但是请注意,使用时一个大的结果等于若干个小的部分合并的结果,所以要求的数据必须满足结合律并且可以差分。
区间
具体区间怎么拆呢?
可以看一下OIwiki上的这个图:
事实上,c[x]的管辖区间就是x向左lowbit(x)个单位,而lowbit(x)就是x二进制最低位1以及后面的0组成的数为lowbit,例如1010100的lowbit就是100,实现如下。
1 2 3 int lowbit (int x) return x&-x;
建树
很显然,如果进行n次单点修改未免太慢了,那么正难则反,我们可以想到倒着考虑贡献,实现O(n)方案!
每次确定完儿子的值后,用自己的值更新自己的直接父亲就好了。
1 2 3 4 5 6 7 8 void init () for (int i=1 ;i<=n;i++){ int j=i+lowbit (i); if (j<=n) t[j]+=t[i];
区间查询
因为树状数组是区间储存,所以要查询lr可以将1 r-1~l就可以得到要求值了。
但是怎么查询1~x呢?
其实t[x]储存的是x-lowbit(x)+1~x,那么我们可以一点点往前回溯,最后把得到的值都加起来就好了。
1 2 3 4 5 6 7 8 int getsum (int x) int ans=0 ; while (x>0 ){ lowbit (x); return ans;
单点修改
显然,我们只需要不断修改父亲节点就好了,注意不要越界。
1 2 3 4 5 6 void add (int b,int c) while (b<=n){ lowbit (b);
做一道模板题试试吧!
例题1:模板 描述
如题,已知一个数列,你需要进行下面两种操作:
输入描述
第一行包含两个正整数n,m,分别表示该数列数字的个数和操作的总个数。
第二行包含n个用空格分隔的整数,其中第i个数字表示数列第i项的初始值。
接下来m行每行包含3个整数,表示一个操作,具体如下:
1 x k含义:将第x个数加上k
2 x y含义:输出区间[x,y]内每个数的和
输出描述
输出包含若干行整数,即为所有操作2的结果。
解答 分析
模板
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;const int N=5e5 +5 ;int n,m;int a[N],t[N];int lowbit (int x) return x&-x;void init () for (int i=1 ;i<=n;i++){int j=i+lowbit (i);if (j<=n) t[j]+=t[i];void add (int b,int c) while (b<=n){t[b]+=c;b+=lowbit (b);}int getsum (int x) int ans=0 ;while (x>0 ){lowbit (x);return ans;int main () for (int i=1 ;i<=n;i++) cin>>a[i];init ();for (int i=1 ;i<=m;i++){int a,b,c;if (a==1 ) add (b,c);else getsum (c)-getsum (b-1 )<<endl;return 0 ;
区间加和
如果我们要区间加和怎么办呢?很显然依次加很慢,我们就想到了使用差分。
很显然,储存时应当直接进行差分操作。
对于区间修改:我们只需修改头与尾,即l节点+k,r+1节点-k
对于区间查询:差分的逆运算是前缀和,所以我们需要把各个点加在一起(其实没有什么区别)。
这就是区间树状数组啦!
例题2:模板 描述
如题,已知一个数列,你需要进行下面两种操作:
输入描述
第一行包含两个正整数n,m,分别表示该数列数字的个数和操作的总个数。
第二行包含n个用空格分隔的整数,其中第i个数字表示数列第i项的初始值。
接下来m行每行包含2或4个整数,表示一个操作,具体如下:
输出描述
输出包含若干行整数,即为所有操作2的结果。
解答 分析
模板
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <bits/stdc++.h> using namespace std;const int N=5e5 +5 ;int n,m;int a[N]; int t[N]; int lowbit (int x) return x&-x;void add (int pos,int val) while (pos<=n){lowbit (pos);int getsum (int pos) int res=0 ;while (pos>0 ){lowbit (pos);return res;int main () for (int i=1 ;i<=n;i++) cin>>a[i];for (int i=1 ;i<=n;i++){add (i, a[i]-a[i-1 ]);for (int i=1 ;i<=m;i++){int op;if (op==1 ){ int l,r,k;add (l, k); add (r+1 , -k); else { int x;getsum (x)<<endl; return 0 ;
做一道比较难的提升题吧!
例题3:P1908 逆序对 题目描述
猫猫 TOM 和小老鼠 JERRY 最近又较量上了,但是毕竟都是成年人,他们已经不喜欢再玩那种你追我赶的游戏,现在他们喜欢玩统计。
最近,TOM 老猫查阅到一个人类称之为“逆序对”的东西,这东西是这样定义的:对于给定的一段正整数序列,逆序对就是序列中 a i > a j a_i>a_j a i > a j i < j i<j i < j
Update:数据已加强。
输入格式
第一行,一个数 n n n n n n
第二行 n n n 10 9 10^9 1 0 9
输出格式
输出序列中逆序对的数目。
输入输出样例 #1
输入 #1
输出 #1
说明/提示
对于 25 % 25\% 25% n ≤ 2500 n \leq 2500 n ≤ 2500
对于 50 % 50\% 50% n ≤ 4 × 10 4 n \leq 4 \times 10^4 n ≤ 4 × 1 0 4
对于所有数据,1 ≤ n ≤ 5 × 10 5 1 \leq n \leq 5 \times 10^5 1 ≤ n ≤ 5 × 1 0 5
应该不会有人 O ( n 2 ) O(n^2) O ( n 2 )
解答 分析
正难则反,从左往右找逆序对很难,可以从右往左找右边比左边小的点的个数.
使用树状数组储存每个元素的出现次数,而比某个元素小,且在它之后的元素的总数量就是该元素逆序对个数。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <bits/stdc++.h> using namespace std;const int N=5e5 +5 ;int n,m;int a[N],b[N],c[N];int lowbit (int x) return x&-x;void add (int x,int y) for (int i=x;i<=m;i+=lowbit (i)){int sum (int x) int res=0 ;for (int i=x;i;i-=lowbit (i)){return res;int main () int n;for (int i=1 ;i<=n;i++){sort (b+1 ,b+n+1 ); unique (b+1 ,b+n+1 )-b-1 ; long long ans=0 ;for (int i=n;i;i--){ int k=lower_bound (b+1 ,b+m+1 ,a[i])-b; sum (k-1 );add (k,1 );return 0 ;
堆 引入
什么是堆?堆是一棵树,其每个节点都有一个键值,且每个节点的键值都大于等于/小于等于其父亲的键值。说白了就是能够把其中的值自动排序,从小到大的叫小根堆,从大到小的叫大根堆。
实现
实现堆的方法有很多,我们从不常见到常见一一叙述。
STL建堆
顾名思义,使用STL的make_heap建堆,不多赘述。
手动建堆
插入:可以将要插入的点放在最后,不断向上交换直到满足权值大小要求。
删除:通常指删除根结点,将根节点与最后一个点交换,删除根节点(目前最后一个点),将目前的根节点不断向下交换直到满足权值大小要求。
以下是向上/下交换的代码,默认小根堆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void up (int x) while (x>1 &&h[x]>h[x/2 ]){swap (h[x],h[x/2 ]);2 ;void down (int x) while (x*2 <=n){2 ;if (t+1 <=n&&h[t+1 ]>h[t]) t++;if (h[t]<=h[x]) break ;swap (h[x],h[t]);
建堆:将每个点依次上调或者下调。
1 2 3 4 5 6 7 8 void build1 () for (int i=1 ;i<=n;i++) up (i);void build2 () for (int i=n;i>=1 ;i--) down (i);
优先队列
1 2 priority_queue<int > p1; int ,vector<int >,greater<int >> p2;
那就来做一道简单的题吧。
例题1:P1090 [NOIP 2004 提高组] 合并果子 G 题目背景
P6033 为本题加强版。
题目描述
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过 n − 1 n-1 n − 1
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为 1 1 1
例如有 3 3 3 1 1 1 2 2 2 9 9 9 1 1 1 2 2 2 3 3 3 3 3 3 12 12 12 12 12 12 = 3 + 12 = 15 =3+12=15 = 3 + 12 = 15 15 15 15
输入格式
共两行。
第一行是一个整数 n ( 1 ≤ n ≤ 10 4 ) n(1\leq n\leq 10^4) n ( 1 ≤ n ≤ 1 0 4 )
第二行包含 n n n i i i a i ( 1 ≤ a i ≤ 2 × 10 4 ) a_i(1\leq a_i\leq 2\times 10^4) a i ( 1 ≤ a i ≤ 2 × 1 0 4 ) i i i
输出格式
一个整数,也就是最小的体力耗费值。输入数据保证这个值小于 2 31 2^{31} 2 31
输入输出样例 #1
输入 #1
输出 #1
说明/提示
对于 30 % 30\% 30% n ≤ 10 3 n \le 10^3 n ≤ 1 0 3
对于 50 % 50\% 50% n ≤ 5 × 10 3 n \le 5\times10^3 n ≤ 5 × 1 0 3
对于全部的数据,保证有 n ≤ 10 4 n \le 10^4 n ≤ 1 0 4
解答 分析
用小根堆模拟即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <bits/stdc++.h> using namespace std;int main () int ,vector<int >,greater<int > >pq;int n,x,ans=0 ;for (int i=1 ;i<=n;i++){push (x);while (pq.size ()>1 ){int t=pq.top ();pop ();top ();pop ();push (t);return 0 ;
负环 引入
在一个含有负边权的图中,如果我们要查找两点间最短路的话,可能会出现一种问题,假如图中有一个负环(就是总边权为负的环),那么因为能够不断减少总边权,通常的最短路算法就会不断地在其中绕圈,这肯定是不行的,于是就有了SPFA算法,它不仅能够判断图中是否存在负环,同时也可以求出含有负边但不含负环的图中的最短路。
值得注意的是SPFA时间复杂度高于Dijkstra算法,所以不含负边时还是应该使用Dijkstra算法。
实现
可以记录到达某一个点经过边的个数,如果多于总共边的个数说明绕圈了,也可以记录一个点入队次数,入队n次则有负环。
注意,有时给的不是一个图而是多个不相连的图,这样应该用一个循环将每个点都入队,而非只将一个点入队。
说实话,SPFA特别好卡,故有SPFA已死的说法,所以写的时候请确定必须使用SPFA。
做一道模板吧!
例题1:P3385 【模板】负环 题目描述
给定一个 n n n 从顶点 1 1 1 的负环。
负环的定义是:一条边权之和为负数的回路。
输入格式
本题单测试点有多组测试数据 。
输入的第一行是一个整数 T T T
第一行有两个整数,分别表示图的点数 n n n m m m
接下来 m m m u , v , w u, v, w u , v , w
输出格式
对于每组数据,输出一行一个字符串,若所求负环存在,则输出 YES,否则输出 NO。
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 9 10 11 2 3 4 1 2 2 1 3 4 2 3 1 3 1 -3 3 3 1 2 3 2 3 4 3 1 -8
输出 #1
说明/提示
数据规模与约定
对于全部的测试点,保证:
1 ≤ n ≤ 2 × 10 3 1 \leq n \leq 2 \times 10^3 1 ≤ n ≤ 2 × 1 0 3 1 ≤ m ≤ 3 × 10 3 1 \leq m \leq 3 \times 10^3 1 ≤ m ≤ 3 × 1 0 3
1 ≤ u , v ≤ n 1 \leq u, v \leq n 1 ≤ u , v ≤ n − 10 4 ≤ w ≤ 10 4 -10^4 \leq w \leq 10^4 − 1 0 4 ≤ w ≤ 1 0 4
1 ≤ T ≤ 10 1 \leq T \leq 10 1 ≤ T ≤ 10
提示
请注意,m m m 不是 图的边数。
解答 分析
模板,但注意本题不能将所有点先行入队。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <bits/stdc++.h> using namespace std;const int N=3e3 ;int t,n,m;struct edge {int v,w;int dis[N],cnt[N],vis[N];bool spfa () memset (dis,0x3f ,sizeof (dis));memset (cnt,0 ,sizeof (cnt));memset (vis,0 ,sizeof (vis));int > q;push (1 );1 ]=1 ,dis[1 ]=0 ;while (q.empty ()==0 ){int u=q.front ();pop ();0 ;for (edge ee:e[u]){int v=ee.v,w=ee.w;if (dis[v]>dis[u]+w){+1 ;if (cnt[v]>n) return false ;if (vis[v]==0 ){push (v);1 ;return true ;int main () while (t--){for (int i=1 ;i<=n;i++) e[i].clear ();for (int i=1 ;i<=n;i++) e[0 ].push_back ({i,0 });int u,v,w;for (int i=1 ;i<=m;i++){if (w>=0 ) e[u].push_back ({v,w}),e[v].push_back ({u,w});else e[u].push_back ({v,w});if (spfa ()) cout<<"NO" <<endl;else cout<<"YES" <<endl;return 0 ;
再实战一下吧!
例题2:P2850 [USACO06DEC] Wormholes G 题目背景
英文题面见此链接
题目描述
Farmer John 在探索他的农场时发现了许多神奇的虫洞。虫洞的特性非常特殊——它是一个单向通道,能将你传送到它的目的地,而且时间还会回溯到过去!FJ 的每个农场包含 N ( 1 ≤ N ≤ 500 ) N (1 \le N \le 500) N ( 1 ≤ N ≤ 500 ) 1 ∼ N 1 \sim N 1 ∼ N M ( 1 ≤ M ≤ 2500 ) M (1 \le M \le 2500) M ( 1 ≤ M ≤ 2500 ) W ( 1 ≤ W ≤ 200 ) W (1 \le W \le 200) W ( 1 ≤ W ≤ 200 )
作为狂热的时间旅行爱好者,FJ 希望实现:从某块田地出发,经过若干路径和虫洞后,在初始离开时间之前回到起点。这样或许他能遇见自己 😃
为了判断可行性,FJ 将提供 F ( 1 ≤ F ≤ 5 ) F (1 \le F \le 5) F ( 1 ≤ F ≤ 5 ) 10 , 000 10,000 10 , 000 10 , 000 10,000 10 , 000
输入格式
第 1 1 1 F F F F F F
每个农场:
第 1 1 1 N N N M M M W W W
第 2 ∼ M + 1 2 \sim M+1 2 ∼ M + 1 ( S , E , T ) (S, E, T) ( S , E , T ) S S S E E E T T T
第 M + 2 ∼ M + W + 1 M+2 \sim M+W+1 M + 2 ∼ M + W + 1 ( S , E , T ) (S, E, T) ( S , E , T ) S S S E E E T T T
输出格式
输出 F F F YES,否则输出NO。
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 9 10 2 3 3 1 1 2 2 1 3 4 2 3 1 3 1 3 3 2 1 1 2 3 2 3 4 3 1 8
输出 #1
说明/提示
翻译:DeepSeek-R1
解答 分析
注意道路是双向的,虫洞是单向的,并将所有点先行入队。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <bits/stdc++.h> using namespace std;const int N=3005 ;int t,n,m,w;struct edge {int v,w;int dis[N],cnt[N],vis[N];bool spfa () memset (dis,0x3f ,sizeof (dis));memset (cnt,0 ,sizeof (cnt));memset (vis,0 ,sizeof (vis));int > q;push_back (1 );1 ]=1 ,dis[1 ]=0 ;while (q.empty ()==0 ){int u=q.front ();pop ();0 ;for (edge ee:e[u]){int v=ee.v,w=ee.w;if (dis[v]>dis[u]+w){+1 ;if (cnt[v]>n){return 1 ;}if (vis[v]==0 ){push (v);1 ;return 0 ;int main () while (t--){for (int i=1 ;i<=n;i++) e[i].clear ();for (int i=1 ;i<=n;i++) e[0 ].push_back ({i,0 });int u,v,p;for (int i=1 ;i<=m;i++){push_back ({v,p});push_back ({u,p});for (int i=1 ;i<=w;i++){2 *p; push_back ({v,p});if (spfa ()) cout<<"YES" <<endl;else cout<<"NO" <<endl;return 0 ;
差分约束 引入
差分约束就是要求你求解由若干个形如x i − x j ≤ c k x_i-x_j\leq c_k x i − x j ≤ c k
解决
x i − x j ≤ c k x_i-x_j\leq c_k x i − x j ≤ c k x i ≤ x j + c k x_i\leq x_j+c_k x i ≤ x j + c k d i s [ v ] ≤ d i s [ u ] + z dis[v]\leq dis[u]+z d i s [ v ] ≤ d i s [ u ] + z x i x_i x i
但是在具体实现中要注意,很多时候并不是每两个未知数之间都给予了条件,所以需要使用超级源点。
注意到这样的不等式组一定能简化成形如x i ≤ x i + m x_i\leq x_i+m x i ≤ x i + m
这里给个标程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <bits/stdc++.h> using namespace std;const int N=5e3 +5 ;int n,m;struct edge {int v,w;int dis[N],cnt[N],vis[N];bool spfa () memset (dis,0x3f ,sizeof (dis));int > q;push (0 );0 ]=1 ,dis[0 ]=0 ;while (q.empty ()==0 ){int u=q.front ();pop ();0 ;for (edge ee:e[u]){int v=ee.v,w=ee.w;if (dis[v]>dis[u]+w){+1 ;if (cnt[v]>n+1 ) return false ; if (vis[v]==0 ){push (v);1 ;return true ;int main () for (int i=1 ;i<=n;i++) e[0 ].push_back ({i,0 });int uu,vv,ww;for (int i=1 ;i<=m;i++){push_back ({uu,ww});if (spfa ()==false ) cout<<"NO" <<endl;else for (int i=1 ;i<=n;i++) cout<<dis[i]<<" " ;return 0 ;
接下来做一道简单的例题吧。
例题1:P1993 小 K 的农场 题目描述
小 K 在 MC 里面建立很多很多的农场,总共 n n n m m m
农场 a a a b b b c c c
农场 a a a b b b c c c
农场 a a a b b b
但是,由于小 K 的记忆有些偏差,所以他想要知道存不存在一种情况,使得农场的种植作物数量与他记忆中的所有信息吻合。
输入格式
第一行包括两个整数 n n n m m m
接下来 m m m
如果每行的第一个数是 1 1 1 a , b , c a,b,c a , b , c a a a b b b c c c
如果每行的第一个数是 2 2 2 a , b , c a,b,c a , b , c a a a b b b c c c
如果每行的第一个数是 3 3 3 a , b a,b a , b a a a b b b
输出格式
如果存在某种情况与小 K 的记忆吻合,输出 Yes,否则输出 No。
输入输出样例 #1
输入 #1
1 2 3 4 5 3 3 3 1 2 1 1 3 1 2 2 3 2
输出 #1
说明/提示
对于 100 % 100\% 100% 1 ≤ n , m , a , b , c ≤ 5 × 10 3 1 \le n,m,a,b,c \le 5 \times 10^3 1 ≤ n , m , a , b , c ≤ 5 × 1 0 3
解答 分析
根据差分约束基本原理推理一下三种情况的建边方法即可。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> using namespace std;const int N=5e3 +5 ;int n,m;struct edge {int v,w;int dis[N],cnt[N],vis[N];bool spfa () memset (dis,0x3f ,sizeof (dis));int > q;push (0 );0 ]=1 ,dis[0 ]=0 ;while (q.empty ()==0 ){int u=q.front ();pop ();0 ;for (edge ee:e[u]){int v=ee.v,w=ee.w;if (dis[v]>dis[u]+w){+1 ;if (cnt[v]>=n+1 ) return false ;if (vis[v]==0 ){push (v);1 ;return true ;int main () for (int i=1 ;i<=n;i++) e[0 ].push_back ({i,0 });int num,uu,vv,ww;for (int i=1 ;i<=m;i++){if (num==1 ){push_back ({vv,-ww});else if (num==2 ){push_back ({uu,ww});else if (num==3 ){push_back ({uu,0 });push_back ({vv,0 });if (spfa ()==false ) cout<<"No" <<endl;else cout<<"Yes" ;return 0 ;
图的存储 图的存储通常来说是要存储边的起点,终点和边权,而我们有很多不同的方法实现,各有各的用途与快慢,接下来我将按照从慢到快进行介绍。
直接存边
1 2 3 4 5 6 struct edge {int u,v,w;
由于最小生成树需要记录并查集所以会使用这个算法。
邻接矩阵
1 2 3 4 vector<vector<int >> e;
可以很快地查询一条边是否存在,不能用于有重边的情况。
邻接表
1 2 3 4 5 6 7 struct edge {int v,w; push_back ({v,w});
几近于万能
链式前向星
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int > head,nxt,to,wgt; int cnt=-1 ; void add (int u,int v,int w) add (u,v,w);for (int i=head[u];i!=-1 ;i=nxt[i]){int v=to[i];
本质就是用手写的链表模拟了邻接表,非常快,也非常难写。
拓扑排序(Kahn算法) 引入
拓扑排序就是一种给有向无环图节点排序的方法,使得前面的节点不依赖后面的节点。
Kahn算法实现
维护一个入度为0的顶点的队列,将这些顶点连接的其它点的入度减1,一直这样下去直到没有点。
注意到如果有环,一个图没有拓扑排序,且环上的节点不会被加入队列,那么我们可以统计加入队列点的个数,如果小于总共点的个数就有环,拓扑排序不能实现。
标程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <bits/stdc++.h> using namespace std;const int N=1e5 +5 ;int n,m;int > s[N];int cnt[N]; int > q; int > ans;void tuopu () for (int i=1 ;i<=n;i++){if (cnt[i]==0 ) q.push (i); while (q.empty ()==0 ){int p=q.front ();pop (); push_back (p);for (int po:s[p]){ if (cnt[po]==0 ) q.push (po); if (ans.size ()<n) cout<<-1 ; else for (int i=0 ;i<n;i++) cout<<ans[i]<<" " ;int main () for (int i=1 ;i<=m;i++){int x,y;push_back (y);tuopu ();return 0 ;
做两道例题吧!
例题1:P1113 [USACO02FEB] 杂务 题目描述
John 的农场在给奶牛挤奶前有很多杂务要完成,每一项杂务都需要一定的时间来完成它。比如:他们要将奶牛集合起来,将他们赶进牛棚,为奶牛清洗乳房以及一些其它工作。尽早将所有杂务完成是必要的,因为这样才有更多时间挤出更多的牛奶。
当然,有些杂务必须在另一些杂务完成的情况下才能进行。比如:只有将奶牛赶进牛棚才能开始为它清洗乳房,还有在未给奶牛清洗乳房之前不能挤奶。我们把这些工作称为完成本项工作的准备工作。至少有一项杂务不要求有准备工作,这个可以最早着手完成的工作,标记为杂务 1 1 1
John 有需要完成的 n n n k ( k > 1 ) k\ (k>1) k ( k > 1 ) 1 1 1 k − 1 k-1 k − 1
写一个程序依次读入每个杂务的工作说明。计算出所有杂务都被完成的最短时间。当然互相没有关系的杂务可以同时工作,并且,你可以假定 John 的农场有足够多的工人来同时完成任意多项任务。
输入格式
第 1 1 1 n ( 3 ≤ n ≤ 10,000 ) n\ (3 \le n \le 10{,}000) n ( 3 ≤ n ≤ 10 , 000 )
第 2 2 2 n + 1 n+1 n + 1
工作序号(保证在输入文件中是从 1 1 1 n n n
完成工作所需要的时间 l e n ( 1 ≤ l e n ≤ 100 ) len\ (1 \le len \le 100) l e n ( 1 ≤ l e n ≤ 100 )
一些必须完成的准备工作,总数不超过 100 100 100 0 0 0 0 0 0
保证整个输入文件中不会出现多余的空格。
输出格式
一个整数,表示完成所有杂务所需的最短时间。
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 9 7 1 5 0 2 2 1 0 3 3 2 0 4 6 1 0 5 1 2 4 0 6 8 2 4 0 7 4 3 5 6 0
输出 #1
解答 分析
由于拓扑排序性质,我们处理节点顺序就已经是最优顺序了,但是确保处理节点时将时间继承到了它的儿子上。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <bits/stdc++.h> using namespace std;const int N=1e4 +5 ;int n;int > s[N];int timee[N];int tim[N]; int cnt[N];int > q;int ans=0 ;void tuopu () for (int i=1 ;i<=n;i++){if (cnt[i]==0 ) q.push (i);while (q.empty ()==0 ){int p=q.front ();pop ();for (int po:s[p]){max (timee[p]+tim[po],timee[po]);max (ans,timee[po]);if (cnt[po]==0 ) q.push (po); int main () for (int i=1 ;i<=n;i++){int x;while (cin>>x){if (x!=0 ){push_back (i);else break ;tuopu ();return 0 ;
例题2:P4017 最大食物链计数 题目背景
你知道食物链吗?Delia 生物考试的时候,数食物链条数的题目全都错了,因为她总是重复数了几条或漏掉了几条。于是她来就来求助你,然而你也不会啊!写一个程序来帮帮她吧。
题目描述
给你一个食物网,你要求出这个食物网中最大食物链的数量。
(这里的“最大食物链”,指的是生物学意义上的食物链 ,即最左端是不会捕食其他生物的生产者,最右端是不会被其他生物捕食的消费者 。)
Delia 非常急,所以你只有 1 1 1
由于这个结果可能过大,你只需要输出总数模上 80112002 80112002 80112002
输入格式
第一行,两个正整数 n n n m m m n n n m m m
接下来 m m m
输出格式
一行一个整数,为最大食物链数量模上 80112002 80112002 80112002
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 5 7 1 2 1 3 2 3 3 5 2 5 4 5 3 4
输出 #1
说明/提示
各测试点满足以下约定:
测试点编号
n n n m m m
1 , 2 1,2 1 , 2 ≤ 40 \le 40 ≤ 40 ≤ 400 \le 400 ≤ 400
3 , 4 3,4 3 , 4 ≤ 100 \le 100 ≤ 100 ≤ 2 × 10 3 \le 2\times 10^3 ≤ 2 × 1 0 3
5 , 6 5,6 5 , 6 ≤ 10 3 \le 10^3 ≤ 1 0 3 ≤ 6 × 10 4 \le 6\times 10^4 ≤ 6 × 1 0 4
7 , 8 7,8 7 , 8 ≤ 2 × 10 3 \le 2\times 10^3 ≤ 2 × 1 0 3 ≤ 2 × 10 5 \le 2\times 10^5 ≤ 2 × 1 0 5
9 , 10 9,10 9 , 10 ≤ 5 × 10 3 \le 5\times 10^3 ≤ 5 × 1 0 3 ≤ 5 × 10 5 \le 5\times 10^5 ≤ 5 × 1 0 5
对于 100 % 100\% 100% 1 ≤ n ≤ 5 × 10 3 , 1 ≤ m ≤ 5 × 10 5 1 \le n \le 5\times 10^3,1\le m \le 5\times 10^5 1 ≤ n ≤ 5 × 1 0 3 , 1 ≤ m ≤ 5 × 1 0 5
【补充说明】
数据中不会出现环,满足生物学的要求。(感谢 @AKEE)
解答 分析
生产者入度为0,顶级消费者出度为0,也需要判断出度,来知道停止条件。
注意食物链是加的关系。
标程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <bits/stdc++.h> using namespace std;#define int long long const int MOD=80112002 ,N=500005 ;int n,m;int > s[N];int cnt[N];int > q;int ans=0 ;int num[N];void tuopu () for (int i=1 ;i<=n;i++){if (cnt[i]==0 ){push (i);1 ; while (q.empty ()==0 ){ int p=q.front ();pop ();if (s[p].empty ()==1 ){ else for (int po:s[p]){if (cnt[po]==0 ) q.push (po); signed main () for (int i=1 ;i<=m;i++){int x,y;push_back (y);tuopu ();return 0 ;